
Optimización de Rendimiento en Interactive Reports
Cuando lo "Flexible" se vuelve "Lento"

Lo has visto antes: un reporte que funcionaba perfectamente en desarrollo con 100 filas comienza a "congelarse" o a mostrar el famoso "spinner" por 5 minutos en producción con 100,000 registros. ¿La reacción inmediata? "Agrega un índice" o "La base de datos está lenta".
Como consultor, he descubierto que el cuello de botella en los Interactive Reports (IR) de Oracle APEX rara vez es solo la falta de un índice. Generalmente, es un desajuste entre cómo el motor de APEX genera la consulta envolvente (wrapper) y cómo está escrito tu origen SQL. Un Interactive Report no es un simple SELECT * FROM tabla; es un generador de consultas complejo y dinámico que añade capas de cláusulas WHERE, funciones analíticas para paginación y cálculos de estado de sesión.
Si tratas a un Interactive Report como una tabla estática, estás abdicando de tu responsabilidad como Ingeniero de Software. En este APEX Insight, pasamos del desarrollo de "arrastrar y soltar" a una arquitectura de rendimiento intencional.
El Desafío Arquitectónico
¿Por qué es más difícil optimizar un IR que un reporte estándar? Por la Complejidad Dinámica. Cuando un usuario agrega un filtro, ordena una columna o calcula una suma, APEX modifica el plan de ejecución sobre la marcha.
El desafío reside en los Costos Variables del Estado de Sesión. Acceder a :APP_ITEM o :P_ITEM dentro de tu origen SQL es eficiente; el verdadero costo aparece cuando llamas a funciones PL/SQL o APIs de APEX como V('P1_ITEM') dentro del SQL, lo que obliga a cambios de contexto constantes. Además, la función "Total Row Count" —la favorita de los usuarios— es a menudo un asesino silencioso, forzando un escaneo completo solo para mostrar una etiqueta de "1-50 de 10,000".
Anatomía de la "Consulta Envolvente" (Wrapper Query)
To master performance, you must understand what happens behind the scenes. APEX doesn't just run your SQL; it wraps it in layers of complexity to handle filtering, sorting, and pagination.
If your query is SELECT * FROM pedidos, APEX eventually generates something like this:
SELECT * FROM (
SELECT a.*, COUNT(*) OVER () AS total_rows, ROWNUM AS rn
FROM (
-- TU ORIGEN SQL COMIENZA AQUÍ
SELECT * FROM pedidos ORDER BY fecha_pedido DESC
-- TU ORIGEN SQL TERMINA AQUÍ
) a
WHERE a.estado_pedido = 'ABIERTO' -- Filtro dinámico añadido por usuario
) WHERE rn BETWEEN 1 AND 50;
La Zona de Peligro: si tienes un ORDER BY dentro de tu SQL origen, y el usuario añade otro ordenamiento a través de la interfaz del IR, la base de datos podría realizar una operación de doble ordenamiento. Peor aún, si tu SQL origen es una vista compleja, el optimizador podría fallar al intentar "empujar" los filtros del usuario hacia las tablas base, causando que todo el conjunto de datos se materialice en memoria antes de que se identifiquen siquiera las primeras 50 filas.
graph LR
UserSQL["Origen SQL del Usuario"] --> APEXWrapper["Consulta Envolvente de APEX"]
APEXWrapper --> Analytics["Analíticas (Count Over, Rank)"]
Analytics --> Pagination["Filtro Top-N (ROWNUM <= 50)"]
subgraph "El Lado de la Base de Datos"
APEXWrapper
Analytics
Pagination
end
Modelos Mentales: La Regla de las 100 Filas
En lugar de pensar "¿Qué tan rápido puedo consultar 1 millón de filas?" pregúntate: "¿Qué tan eficientemente puedo entregar las primeras 50?"
Los Interactive Reports están diseñados para la paginación. Tu modelo mental debería ser: la base de datos solo debería hacer el trabajo equivalente a 100 filas para mostrar 50 filas de datos. Si tu plan de ejecución muestra un SORT AGGREGATE o un HASH JOIN a través de todo el conjunto de datos antes de devolver la primera página, tu arquitectura ha fallado la "Prueba de Paginación".
| Enfoque | Tiempo Transcurrido (Segundos) |
|---|---|
| Ingenuo (Cuenta Total) | 100 |
| Optimizado (Lazy Count) | 7 |
Riesgo de Timeout: En nuestro benchmark en vivo, el enfoque "Ingenuo" a menudo genera un timeout de gateway porque calcular el total de 100,000 filas lentas excedió el límite del servidor. El enfoque "Optimizado", sin embargo, devuelve la primera página en aproximadamente 7 segundos (procesando solo el buffer necesario de filas).
Patrones Estratégicos
Evita poner lógica de negocio compleja en la cláusula WHERE de tu SQL del reporte si esos filtros pueden ser manejados por los filtros declarativos de APEX. Si la lógica es realmente compleja, muévela a una SQL Macro (si estás en 21c+) o a una Vista para permitir que el optimizador "vea a través" de la complejidad.
2. El Patrón "Lazy Count"
Desactiva el "Total Row Count" para tablas masivas. Usa la configuración "Row Ranges X to Y" o implementa un conteo separado y cacheado si es necesario. Forzar al motor a contar 5M de filas en cada refresco no es una funcionalidad; es un error de diseño.
Configuración del Page Designer
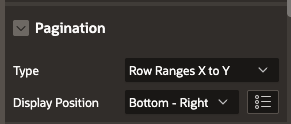
Resaltando la pestaña 'Attributes' del Interactive Report, específicamente el 'Type' configurado como 'Row Ranges X to Y' para el patrón de conteo perezoso.
3. Optimización del Estado de Sesión
Nunca hagas un join con dual para obtener ítems ni uses nvl(:P1_ITEM, col). Usa los mecanismos de filtrado de IR de APEX o asegúrate de que tu SQL use variables de vinculación (bind variables) que el optimizador pueda usar para la poda de particiones (partition pruning).
4. Aprovechamiento del Result Cache
Si el origen de tu reporte es una agregación pesada que depende de datos que no cambian cada segundo (ej., "Resumen de Ventas Diarias"), usa el hint /*+ RESULT_CACHE */. Esto permite que la base de datos almacene el resultado en la SGA, sirviendo a los usuarios subsiguientes en milisegundos sin re-ejecutar el SQL pesado.
Escuchando al Optimizador: Observabilidad
Un Arquitecto Senior nunca adivina; mide. Para inspeccionar cómo APEX modifica tu SQL, ejecuta tu página con debug=LEVEL9 y busca la entrada ...preparing statement....
APEX Debug Log - SQL Envuelto Nivel 9

La sentencia SQL final enviada a la base de datos, incluyendo la cláusula COUNT() OVER (). Solo disponible en Nivel 9 de Debug.*
- Explain Plan: Copia ese SQL envuelto y ejecuta un
EXPLAIN PLANen SQL Developer o SQL Workshop.
¿Ves un TABLE ACCESS FULL en una tabla masiva? ¿El COST se dispara por un bucle anidado? Esta es la verdad. Si ves un costo alto en el paso de paginación, es señal de que tu SQL origen bloquea al optimizador para usar índices en el ordenamiento.
Implementación Técnica
Este código utiliza llamadas a funciones en el SELECT y realiza un filtrado pesado dentro del SQL, lo que dificulta la paginación de APEX.
-- ❌ PELIGROSO: Poca escalabilidad
SELECT id,
order_number,
order_date,
get_customer_name(customer_id) as customer, -- Cambio de contexto por fila
(SELECT SUM(amount) FROM order_items WHERE order_id = o.id) as total
-- Subconsulta escalar
FROM orders o
WHERE status = :P1_STATUS -- Si :P1_STATUS es nulo, esto podría causar un
OR :P1_STATUS IS NULL -- full scan
El Enfoque del Consultor (Código BUENO)
Usamos una vista materializada o un join bien indexado y movemos la lógica a la capa de arquitectura.
-- ✅ SEGURO: Optimizado para el optimizador
SELECT o.id,
o.order_number,
o.order_date,
c.customer_name as customer,
o.order_total -- Mantén los totales pre-calculados/agregados en la tabla
-- de origen
FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.status = :P1_STATUS
Nota: asegúrate de que status y customer_id estén indexados. Usa los atributos de "Link to Page" o "Filter" en APEX para manejar criterios opcionales.
La teoría es buena, pero ver la respuesta en milisegundos en una tabla de un millón de filas es mejor. Hemos preparado una aplicación de demostración en vivo donde puedes comparar los enfoques "Ingenuo" y "Consultor" lado a lado.
PRECAUCIÓN: Si haces clic en el informe "Naive", prepárate para una larga espera o un error 504 Gateway Timeout. Este es el comportamiento esperado para demostrar el costo arquitectónico de "Total Row Count".
Recursos de Código Abierto
¿Quieres replicar esta prueba en tu propio entorno? Hemos liberado el script de generación de datos y la configuración de la aplicación en nuestro repositorio complementario.
Script de Generación de Datos: Crea 1M de registros de prueba en segundos.
Configuración de Página: Mira los atributos específicos de IR usados para el patrón "Lazy Count".
📦 Acceder al Código Fuente en GitHub
Errores Comunes
Funciones Analíticas en el SQL Origen:
RANK()oOVER()bloquean al motor para realizar una paginación eficiente de tipo top-N. La base de datos debe calcular el rango para cada fila antes de decidir qué 50 mostrar.Demasiadas Columnas: Las columnas ocultas se siguen obteniendo y procesando. Si no la vas a mostrar, no la selecciones.
Sentencias Case Complejas en el Order By: Evita permitir que los usuarios ordenen por columnas que requieran transformaciones
CASEpesadas.
graph TD
A[Usuario Solicita Página] --> B{¿Cuenta Total Activa?}
B -- Sí --> C[Escaneo Completo + Conteo]
B -- No --> D[Optimización Top-N]
C --> E[Obtener Primeras 50 Filas]
D --> E
E --> F[Renderizar HTML]
style C fill:#f96,stroke:#333
style D fill:#6f6,stroke:#333
Lista de Verificación del Consultor
[ ] ¿Está desactivado el "Total Row Count" para tablas de más de 100k filas?
[ ] ¿El SQL origen usa
:ITEM? (EvitaV('ITEM')para bind variables).[ ] ¿Hay subconsultas escalares o funciones PL/SQL en la lista del
SELECT?[ ] ¿Has revisado el Plan de Ejecución específicamente para la consulta envolvente de APEX?
[ ] ¿Está el atributo "Maximum Row Count" configurado a un límite sensato (por ejemplo, 10,000)?
💡 Bonus: Checklist de Optimización de Rendimiento
No permitas que tus Interactive Reports sean lentos en producción. Descarga nuestra Checklist Completa de Rendimiento para Oracle APEX y asegura que cada informe que entregues esté construido para escalar.
Conclusión
El rendimiento en Oracle APEX no se trata solo de escribir SQL rápido; se trata de entender cómo el motor de APEX interactúa con la base de datos. En este APEX Insight, hemos explorado cómo adoptar un modelo mental de "Paginación Primero" y evitar cambios de contexto por fila puede transformar un reporte lento en una interfaz de alto rendimiento.
Recuerda: cada milisegundo ahorrado en la base de datos es un milisegundo devuelto a la productividad de tu usuario.
Referencias
🚀 ¿Necesitas un Experto en APEX?
Ayudo a empresas a facilitar el desarrollo profesional y DevOps en Oracle APEX. Si quieres construir mejores aplicaciones o automatizar tu pipeline, hablemos.
Agendar una llamada | 💼 Conectar en LinkedIn | 🐦 Seguir en X
💖 Apoya mi Trabajo
Si este artículo te resultó útil, ¡considera apoyarme!
GitHub Sponsors | Buy Me a Coffee
Tu apoyo me ayuda a seguir creando demos de código abierto y contenido para toda la comunidad de Oracle APEX. 🚀



